
John Mueller from Google explains how website content can influence whether GoogleBot will scan your site map.

John Mueller from Google answered the question why an error appears in the Search Console when receiving a sitemap, although the server logs show that GoogleBot has successfully uploaded it.
The question was asked on Reddit. The author of the discussion provided a complete list of technical checks that he made to make sure that the sitemap returns the 200 response code, uses the correct XML structure, indexing is allowed, and so on.
The sitemap is technically correct in all respects, but Google Search Console continues to show an error message.
The redditor explained:
“I have a very difficult problem with submitting the sitemap: the status “Could not be received” immediately appears and the error “Sitemap cannot be read” appears in the details. However, I tried everything to make sure that the sitemap was available, and the server logs confirmed that GoogleBot had successfully received the sitemap with the 200 code, and the sitemap itself was valid and contained the URL –loc and lastmod tags.
…The configuration was set up and the sitemap was sent in December 2025, and for many months there were no sitemap bypass status updates — multiple submissions during this time always resulted in the same immediate error. A small number of pages were submitted manually, and all of them were indexed successfully, but the rest of the URLs listed in sitemap.xml , have not been indexed.”
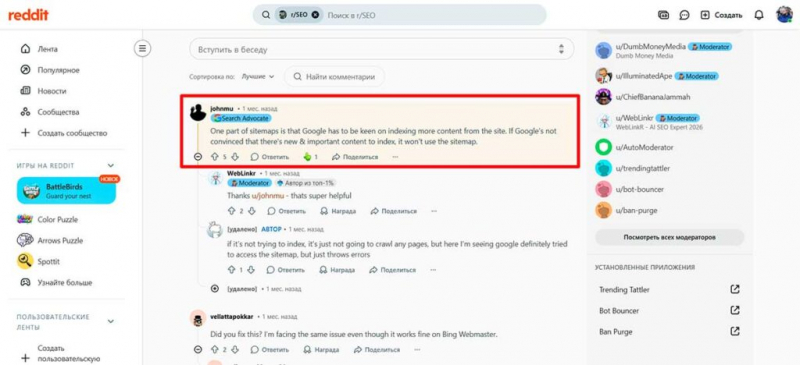
John Mueller from Google answered the question, suggesting that the error message is related to a content issue:
“One of the parts of working with site maps is that Google should be interested in indexing more content from the site. If Google is not convinced that there is new and important content to index, it will not use a sitemap.”
Although Mueller did not use the term “site quality,” it is implied because he says Google should be “interested in indexing more content from the site,” which is “new and important.”
This means two things: it’s possible that the site doesn’t publish a lot of new content, and that this content may not be important. The part about the importance of content is a fairly broad description that can mean a lot, and not all reasons necessarily mean that the content is of poor quality.
Sometimes ranked sites lack an important type of content or structure that helps users better understand a topic or make a decision. It can be an image, a step—by-step guide, a video, or many other things, but not necessarily all at once.
In case of doubt, think like a website visitor and imagine what would be most useful for them. Or the content may be superficial because it is “thin” or non-unique.
Mueller spoke generally, but I believe that returning to what makes a website visitor happy is the best way to find ways to improve the content.