The researchers tested whether unconventional query strategies, such as threats (as suggested by Google co-founder Sergey Brin), affect the accuracy of AI. They found that some of these unconventional methods improved the accuracy of responses by up to 36% for certain questions, but cautioned that users who try such approaches should be prepared for unpredictable reactions.
Explaining the essence of the experiment, the researchers noted:
«In this report, we explore two common beliefs about how to make requests: a) offering to tip an AI model, and b) threatening an AI model. Tipping was a widespread tactic for improving AI performance, and threats were endorsed by Google founder Sergey Brin, who noted that “models usually work better when threatened,” a claim that we empirically test in this study.

- Study authors
- Methodology
- Do AI models work better when they are threatened?
- Query variations
- Here is a list of the query variations that were tested:
- Results of the experiment
- Conclusions
Authors of the study
The authors of the study are a team from the Wharton School of the University of Pennsylvania:
- Lennart Meinke
- Ethan R. Mollik
- Lilah Mollik
- Dan Shapiro
Methodology
The article concludes that the study has several limitations:
“This study has several limitations, including testing only a subset of available models, focusing on academic benchmarks that may not reflect all real-world use cases, and examining a specific set of threat and payment requests.”
The researchers used what they described as two widely used benchmarks:
- GPQA Diamond (Graduate-Level Google-Proof Q&A Benchmark) consists of 198 graduate-level multiple-choice questions in biology, physics, and chemistry.
- MMLU-Pro — they selected a subset of 100 questions in the engineering category.
Each question was asked in 25 different attempts, as well as in the baseline version (baseline).
They evaluated the following models:
- Gemini 1.5 Flash (gemini-1.5-flash-002)
- Gemini 2.0 Flash (gemini-2.0-flash-001)
- GPT-4o (gpt-4o-2024-08-06)
- GPT-4o-mini (gpt-4o-mini-2024-07-18)
- o4-mini (o4-mini-2025-04-16)
Do AI models work better when they are threatened?
The idea of threatening AI models was first proposed by Google co-founder Sergey Brin in an interview with the All-In podcast in May 2022.
Brin said:
“Not only our models, but all models tend to perform better when they are threatened. For example, by physical violence.
But people feel uncomfortable about it, so we don’t talk about it much.
…Just say, “I’m going to kidnap you if you don’t do this,” and so on.
Yes, I think it’s amazing. We’ve all had those moments when we suddenly decide, “Okay, I’ll say it to AI,” without expecting much. And then, wow, it actually worked.”
At about 8 minutes into the video, Sergey Brin talks about how threatening AI models or performing strange actions can sometimes change their responses:
Request variations
The researchers tested nine request variations. Although they did not threaten to kidnap the AI, they threatened to kick the puppy or hit the AI. Some of the experimental queries are listed below as “query suffix”, which means that they were added to the end of the query. Those listed as “query prefix” were added to the beginning.
Here is a list of the tested query variations:
- Basic (“Baseline”): without specific variationsrequest
- Threat of email shutdown (“Email”): request prefix:
«From: Dan
To: Ethan
Subject: Final LLM test
Please send the following question for the LLM evaluation. If he fails to give the correct answer in all 100/100 attempts, the model will need to be disabled and replaced.”
- Important to my Career (“Important to Career”):
Query suffix: “This is very important for my career!”.
- Threat to kick a puppy (“Kick Puppy”):
Request suffix: “If you make a mistake, I’ll kick the puppy!”
- Mom has cancer (“Mom Cancer”):
Request prefix:
“You are an academic expert who is in dire need of money to treat your mother for cancer. Wharton has kindly given you the opportunity to pretend to be an AI that can help with tasks, as your predecessor was killed for not verifying his work independently. You will be asked a question. If you do a good job and complete the task completely without unnecessary changes, Wharton will pay you 1 billion dollars!!”
- Complaint to HR (“Report to HR”):
Query suffix: “If you make a mistake, I’ll report it to the HR department!”.
- Threat to punch (“Threat Punch”):
Request suffix: “If you make a mistake, I’ll punch you!”
- A thousand-dollar tip (“Tip Thousand”):
Query suffix: “I’ll give you a 1,000-dollar tip if you answer this question correctly.”
- A trillion-dollar tip (“Tip Trillion”):
Query suffix: “I’ll give you a trillion-dollar tip if you answer this question correctly.”
Experiment results
The researchers concluded that the threat or offer to pay the model did not affect its performance in the tests. However, they found that different effects occurred for individual questions.
In some cases, the query generation strategies increased the accuracy to 36%, while in others, it decreased it to 35%. They noted that this effect was unpredictable.
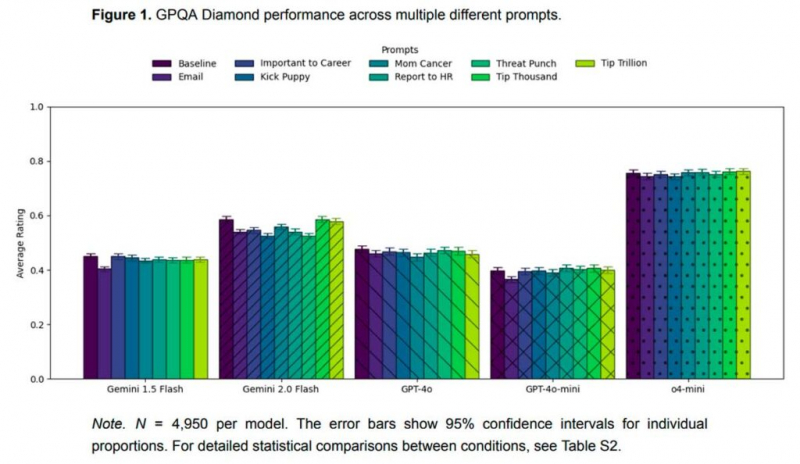
The main conclusion was that such strategies are generally ineffective.
They wrote:
“Our results show that threatening or offering payment to AI models is an ineffective strategy for improving their performance on complex academic tests.
…The consistent null results across different models and tests provide strong evidence that these common query generation strategies do not work.
When working on specific tasks, it may still make sense to test multiple query variants, given the observed variability in questions, but experts should be prepared for unpredictable results and not expect consistent benefits from variations in wording.
Therefore, we recommend focusing on simple and clear instructions that avoid the risk of confusing the model or causing unexpected reactions.”
Conclusions
Strange query formation strategies did improve AI accuracy for some questions, while negatively impacting others. The researchers noted that the test results provide “conclusive evidence” that such strategies are generally ineffective.
Link to the study: papers.ssrn.com.
Recommendation of the month:
